一、功能概述
论文效果视频:https://youtu.be/PCBTZh41Ris
给定一个源视频人物和另一个目标人物的视频,我们的目标是生成一个新目标人的视频,做出与源视频中的人物相同的动作。
这一问题可以看作是每一帧上图像到图像的转换,同时保证时间和空间的流畅。用动作探测器作为源视频和目标视频中间的表示(火柴人模型,这个部分使用openpose完成 https://github.com/CMU-Perceptual-Computing-Lab/openpose.git)我们学习了一种从舞者动作画面到目标物体的映射,为了生成的视频的时间平滑性,我们在每个帧上调整前一时间步的预测。为了在我们的结果中增加面部真实感,我们包括一个专门的GAN训练,以产生目标人的面部。
二、方法概述
为了完成这项任务,我们将管道划分为三个阶段
(1)姿势检测,(2)全局姿势归一化(3)从标准化火柴人模型姿势棒图到目标主体的映射。
在姿势检测阶段,我们使用预训练状态的姿势检测器来创建来自源视频的一帧的火柴人模型。全局姿势标准化阶段考虑了源人物和目标人物形状与框架内位置之间的差异。最后,我们设计了一个系统来学习从标准化的姿势棒图到具有对抗训练的目标人的图像的映射。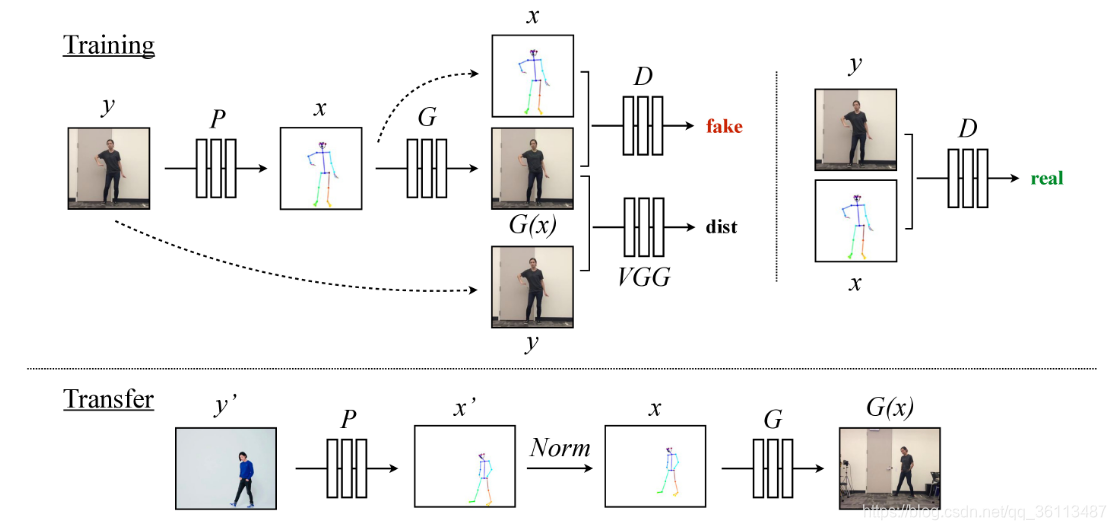
如图2的训练设置中所示。给定来自原始目标视频的帧y,我们使用姿势检测器P来获得相应的火柴人模型x=P(y)。在训练期间,我们使用相应的(x,y)对来学习映射G,该映射G合成给定姿势的火柴人x的目标人物的图像。通过使用预训练的VGGNet模型进行具有鉴别器D和感知重建损失的对抗训练,我们优化生成的输出G(x)以类似于地面实况目标主体帧y。D试图区分“真实”图像对(即(姿势棒图x,地面实况图像y))和“假”图像对(即(姿势棒图x,模型输出G(x))。
转换设置显示在图2的转换设置中。与训练类似,姿势检测器P从源帧y‘中提取姿势信息,产生姿势棒图x’。但是,在视频中,源人物可能看起来更大或更小,并且站在与目标视频中的人物不同的位置。为了使源姿势更好地与目标的拍摄设置对齐,我们应用全局姿势归一化N orm来将源的原始姿势x‘变得为与目标视频x中的姿势更加一致。然后,我们将标准化的姿势棒图x传递到我们训练的模型G中,以获得我们的目标人物的图像G(x),其对应于源y’的原始图像。
三、详细的方法
3.1姿势估计
我们使用姿势估计器p(实际上为openpose)估计关节的坐标,然后将关节画成火柴人模型(姿势棒图)如图3所示。
3.2全局姿势标准化
在不同的视频中,目标人物可能具有不同的肢体比例;靠近或远离相机。因此,当在两个对象之间传送运动姿势时,可能需要变换源视频人物的姿势关键点,使关键点能根据目标人物的身体形状和比例产生,如图2的转换部分一样。我们通过分析每个目标的姿势的高度和脚踝位置来找到这种变换,并使用两个视频中最近和最远的脚踝位置之间的线性映射。收集这些统计数据后,我们根据相应的姿势检测计算每个帧的比例和平移。有关全局姿态归一化的更多详细信息,请参见论文中的第9节的附录。
3.3图像到图像的改进
在GAN部分生成图片主要使用的pix2pixHD这篇论文的模型(论文 http://openaccess.thecvf.com/content_cvpr_2018/papers/Wang_High-Resolution_Image_Synthesis_CVPR_2018_paper.pdf 在这个基础上将pix2pixHD的对抗训练设置修改为(1)产生时间上相干的视频帧,(2)合成逼真的脸部图像。以下是原始目标和对他们的修改的描述。
3.3.1 pix2pixHD
(1)pix2pix
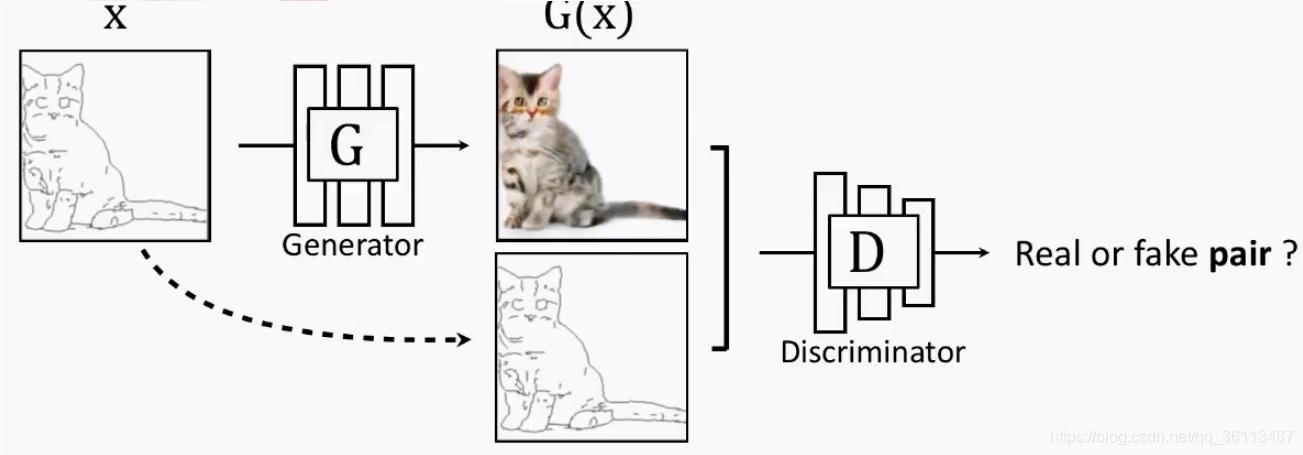
给定语义标签图和对应的真实照片集 (si,xi),该模型中的生成器用于从语义标签图生成出真实图像,而判别器用于区分真实图像和生成的图像,该条件GANs对应的优化问题如下:
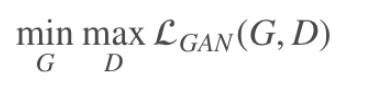
其中: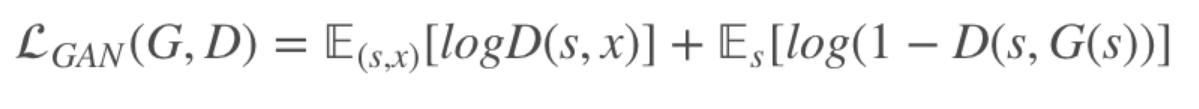
(2)Coarse-to-fine 生成器
由粗到精的G网络,整个G网络其实是由两个子网络构成:G1(棕色框里面的)和G2(两个黑色框里面的)。G1网络负责生成1024512的图片,而G2(G1的信息会输入到G2中)则生成20481024的图片。G1网络由一个用来下采样的前端网络,一系列的ressidual block 以及一个用来上采样的后端网络构成。G2网络也差不多。训练的时候,先训练G1网络,然后训练G2网络,最后联合一起训练G1和G2网络。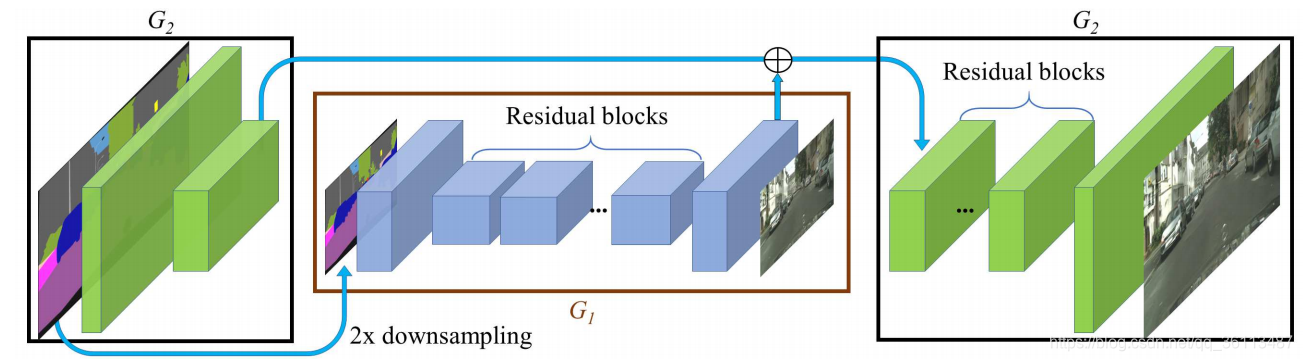
(3)Multi-scale 判别器
要在高分辨率下区分真实的与合成的图像,就要求判别器有很大的感受野,这需要更深的网络或者更大的卷积核才能实现,而这两种选择都会增加网络容量从而使网络更容易产生过拟合问题,并且训练所需的存储空间也会增大。这里用 3 个判别器 {D1,D2,D3} 来处理不同尺度的图像,它们具有相同的网络结构: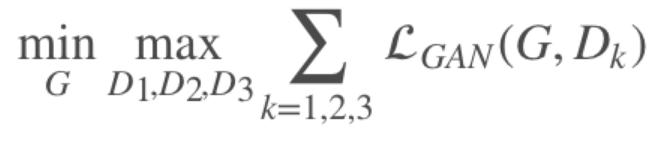
(4)鉴别器特征匹配损失
由于生成器要产生不同尺度的图像,为使训练更加稳定,这里引入特征匹配损失: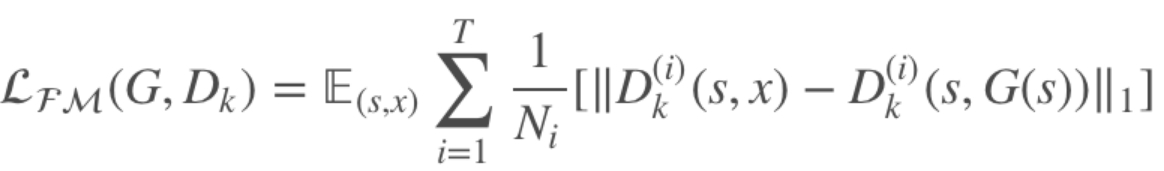
其中 D(i)k表示判别器 Dk 提取的第 i 层特征,T 为总的层数,Ni 为该层总元素的个数。于是,总的目标函数如下: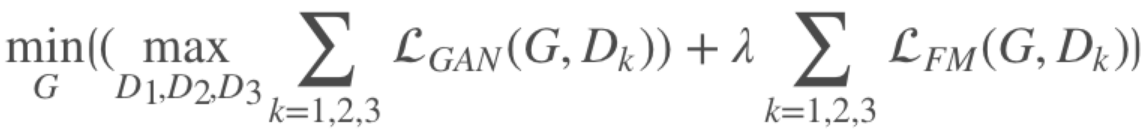
(5)综合来看pix2pixHD这个框架可以描述为:
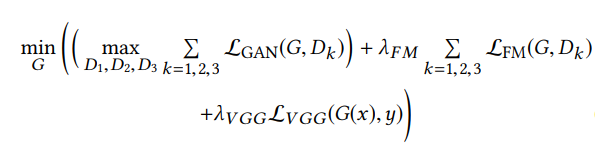
其中对抗性损失为: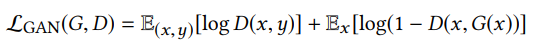
Lfm为pix2pixHD中出现的鉴别器特征匹配损失
Lvgg为感知重建损失,它比较了网络不同层的预训练VGGNet特征
3.3.2时间平滑
为了创建视频序列,我们修改单个图像生成设置来强制相邻帧之间的时间相干性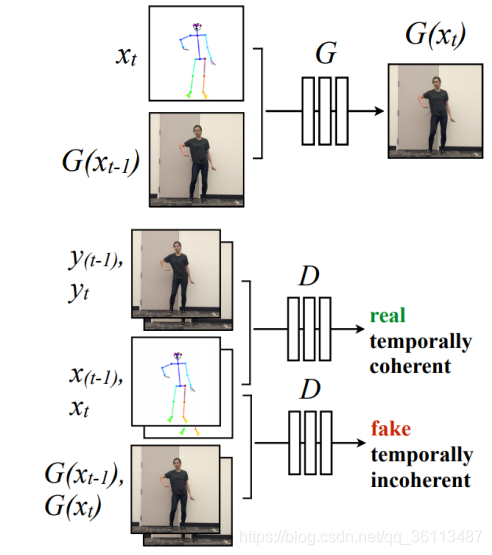
假序列(xt−1, xt ,G(xt−1),G(xt ))真序列(xt−1, xt ,yt−1,yt )所以时间序列的优化目标为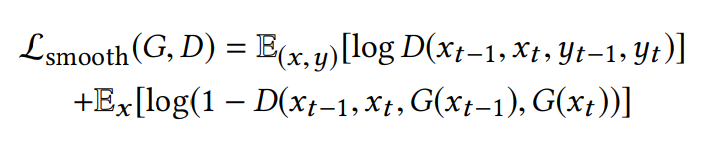
3.3.3脸部GAN
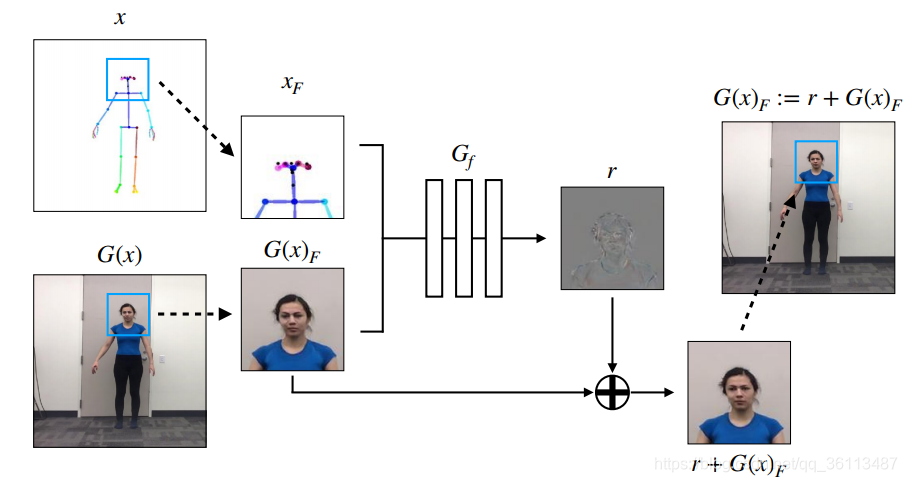
使用主生成器G生成场景的完整图像之后,我们输入以面部G(x)为中心的图像的较小部分和这个部分对应的姿势棒图。r为residual,最后的输出是残差r和原来生成的面部相加。
面部的目标为: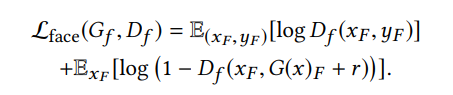
3.3.4整体目标
我们采用分阶段进行训练,其中完整图像GAN与专用面部GAN分开优化。首先,我们训练主生成器和鉴别器(G,D),在此期间完全目标是: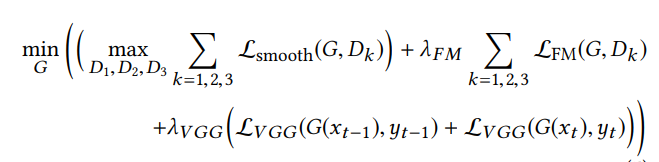
在此阶段之后,完整的图像生成器和鉴别器权重被冻结,我们以完全的目标优化面部GAN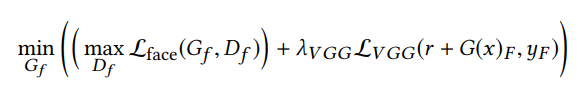
四、数据的需求
以略微不同的方式收集源视频和目标视频。要在拍摄的许多姿势中学习目标人物的外观,我们必须要保证目标人物的视频能够捕获足够的运动范围和具有最小的模糊清晰的帧。为了确保画面的质量,我们以120帧/秒的速度拍摄我们的目标人物约20分钟的实时镜头,这可以通过一些现代手机相机实现。由于我们的姿势表示不会对衣服的信息进行编码,因此我们的目标人物要穿皱纹最小的紧身衣服。
源视频由于我们只是需要人物的姿势,因为没有目标视频那么多要求,网上的很多舞蹈视频都可以满足要求。
我们发现预平滑姿势关键点对减少输出中的抖动非常有帮助。对于具有高帧率(120 fps)的视频,我们随着时间的退役高斯平滑关键点。我们对帧率较低的视频使用中值平滑。




